
Scaling Laws in Large Language Models

A majority of recent advancements in AI research—and large language models (LLMs) in particular—have been driven by scale. If we train larger models over more data, we get better results. This relationship can be defined more rigorously via a scaling law, which is just an equation that describes how an LLM’s test loss will decrease as we increase some quantity of interest (e.g., training compute). Scaling laws help us predict the results of larger and more expensive training runs, giving us the necessary confidence to continue investing in scale.
“If you have a large dataset and you train a very big neural network, then success is guaranteed!” - Ilya Sutskever
For years, scaling laws have been a predictable North Star for AI research. The success of early frontier labs like OpenAI has even been credited to their unwavering belief in scaling laws. However, the continuation of scaling has recently been called into question by reports claiming that top research labs are struggling to create the next generation of better LLMs. These claims lead us to wonder: Will scaling hit a wall, and if so, are there other paths forward?
This article explores these questions from the ground up, beginning with an in-depth explanation of LLM scaling laws and the surrounding research. While the idea of a scaling law is simple, public misconceptions abound—the science behind this research is actually very specific. With this detailed understanding, we will discuss recent trends in LLM research, factors contributing to the “plateau” of scaling laws, and potential avenues for AI progress beyond sheer scale.
Fundamental Scaling Concepts for LLMs
To understand the state of scaling for LLMs, we first need to build a general understanding of scaling laws. This begins with power laws, the foundation of LLM scaling.
What is a Power Law?
Power laws describe a relationship between two quantities. For LLMs, the first of these quantities is the model’s test loss—or another performance metric like downstream task accuracy—and the other is a scaling factor such as the number of model parameters. A typical observation in LLM scaling studies is:
“With enough training data, scaling of validation loss should be approximately a smooth power law as a function of model size.”
Such a statement tells us that increasing the total number of model parameters—assuming sufficient training data—will result in a predictable decrease in test loss.
Here, the negative exponent flips the curve upside down, yielding a log-linear relationship characteristic of most LLM scaling laws. Nearly every paper studying LLM scaling uses plots that show test loss decreasing predictably with more compute, data, or model parameters.
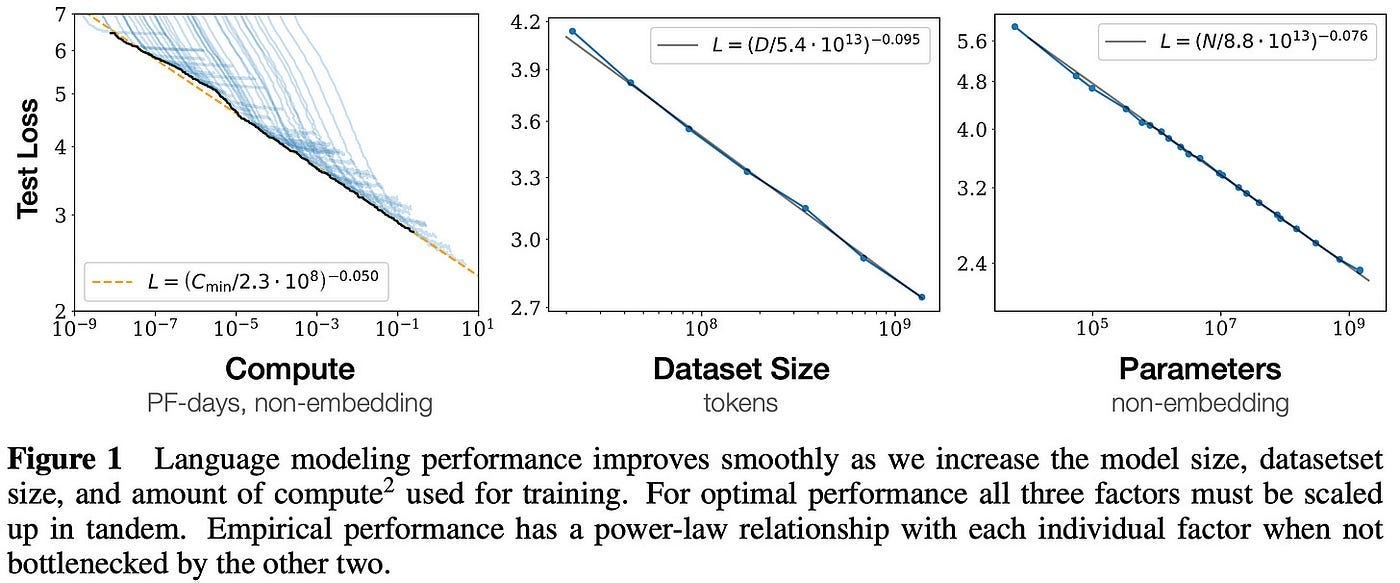
The Origin of Scaling Laws: Key Research
Scaling Laws for Neural Language Models
In early LLM research, the impact of model scale on performance was not well understood. The original GPT model had limited capabilities, and the best way to improve language models was unclear. OpenAI’s seminal work on scaling laws changed this.
“The loss scales as a power-law with model size, dataset size, and the amount of compute used for training, with some trends spanning more than seven orders of magnitude.”
Researchers discovered that LLM performance improves predictably when scaling:
The number of model parameters.
The size of the dataset.
The amount of compute used for training.
However, these improvements are only realized when scaling occurs in tandem—isolating one factor leads to diminishing returns.
Practical Usage of Scaling Laws
Large-scale pretraining is expensive, requiring tens of millions of dollars per training run. This means researchers must predict the performance of larger models before training them. Scaling laws enable this prediction by:
Training smaller models under various conditions.
Fitting scaling laws based on their performance.
Extrapolating results to larger models.
While imperfect, this approach reduces risk and justifies investments in AI research.
The Age of Pretraining and the GPT Lineage
Scaling laws catalyzed recent LLM advancements, particularly in OpenAI’s GPT models:
GPT: Demonstrated self-supervised pretraining’s effectiveness.
GPT-2: Scaled up model size and dataset, introducing zero-shot learning.
GPT-3: A watershed moment, with 175B parameters and strong few-shot learning.
GPT-4: Further improvements, though details remain undisclosed.
Despite these advancements, a natural decay in scaling laws has emerged, leading to concerns about the limits of pretraining.
The “Death” of Scaling Laws
Recent reports suggest LLM scaling may be hitting a wall. Several factors contribute to this perception:
Natural Decay in Scaling Laws: Test loss improves more slowly as models grow larger.
Expectations vs. Reality: AI capabilities are measured subjectively; technical progress may not align with public expectations.
Data Limitations: High-quality training data is finite, and reliance on web scraping may be reaching its limits.
These factors have led to speculation that scaling alone is insufficient for future progress.
The Next Generation of Scaling: Beyond Pretraining
Synthetic Data
To overcome data shortages, researchers are exploring synthetic data generation. While concerns exist about model degeneration, curriculum learning and controlled dataset curation show promise.
Scaling Post-Training and Reasoning Models
Instead of focusing solely on pretraining, researchers are investing in post-training techniques like reinforcement learning. OpenAI’s o1 reasoning model exemplifies this shift, demonstrating that reasoning abilities improve significantly when training reinforcement learning agents to generate structured thought chains.
“o1 thinks before it answers—it can produce a long internal chain of thought before responding.”
Scaling reasoning models—rather than just pretraining—may be the next frontier for AI research.
LLM Systems and Agents
Many AI challenges stem from applying LLMs effectively, not necessarily improving their raw capabilities. Instead of relying on single-model solutions, we can:
Use task decomposition: Breaking complex tasks into manageable subtasks.
Employ tool usage: Augmenting LLMs with external capabilities (e.g., retrieval-augmented generation).
Improve robustness: Developing algorithms that ensure consistent, high-quality outputs.
These strategies will likely drive AI progress in the near future.
The Future of Scaling
Scaling laws have shaped the trajectory of AI research, enabling steady progress in LLM capabilities. However, continued advancements require new strategies beyond brute-force scaling. Key directions include:
Leveraging synthetic data to overcome dataset limitations.
Exploring new scaling paradigms, such as reasoning models.
Developing sophisticated LLM systems that integrate external tools and multi-agent coordination.
While scaling will always play a role, the future of AI research lies in what we choose to scale next. Whether through reasoning models, agent-based systems, or novel architectures, AI’s next breakthroughs will come from refining and expanding upon the foundations that scaling laws have provided.
The question isn’t whether scaling works—it’s how we use it to build something greater.